New Breakthrough Brings Matrix Multiplication Closer to Ideal
Merrill Sherman/Quanta Magazine
Introduction
Computer scientists are a demanding bunch. For them, it’s not enough to get the right answer to a problem — the goal, almost always, is to get the answer as efficiently as possible.
Take the act of multiplying matrices, or arrays of numbers. In 1812, the French mathematician Jacques Philippe Marie Binet came up with the basic set of rules we still teach students. It works perfectly well, but other mathematicians have found ways to simplify and speed up the process. Now the task of hastening the process of matrix multiplication lies at the intersection of mathematics and computer science, where researchers continue to improve the process to this day — though in recent decades the gains have been fairly modest. Since 1987, numerical improvements in matrix multiplication have been “small and … extremely difficult to obtain,” said François Le Gall, a computer scientist at Nagoya University.
Now, three researchers — Ran Duan and Renfei Zhou of Tsinghua University and Hongxun Wu of the University of California, Berkeley — have taken a major step forward in attacking this perennial problem. Their new results, presented last November at the Foundations of Computer Science conference, stem from an unexpected new technique, Le Gall said. Although the improvement itself was relatively small, Le Gall called it “conceptually larger than other previous ones.”
The technique reveals a previously unknown and hence untapped source of potential improvements, and it has already borne fruit: A second paper, published in January, builds upon the first to show how matrix multiplication can be boosted even further.

Renfei Zhou helped find a new method to multiply matrices faster than ever before.
Wei Yu
“This is a major technical breakthrough,” said William Kuszmaul, a theoretical computer scientist at Harvard University. “It is the biggest improvement in matrix multiplication we’ve seen in more than a decade.”
Enter the Matrix
It may seem like an obscure problem, but matrix multiplication is a fundamental computational operation. It’s incorporated into a large proportion of the algorithms people use every day for a variety of tasks, from displaying sharper computer graphics to solving logistical problems in network theory. And as in other areas of computation, speed is paramount. Even slight improvements could eventually lead to significant savings of time, computational power and money. But for now, theoreticians are mainly interested in figuring out how fast the process can ever be.
The traditional way of multiplying two n-by-n matrices — by multiplying numbers from each row in the first matrix by numbers in the columns in the second — requires n3 separate multiplications. For 2-by-2 matrices, that means 23 or 8 multiplications.


Merrill Sherman/Quanta Magazine
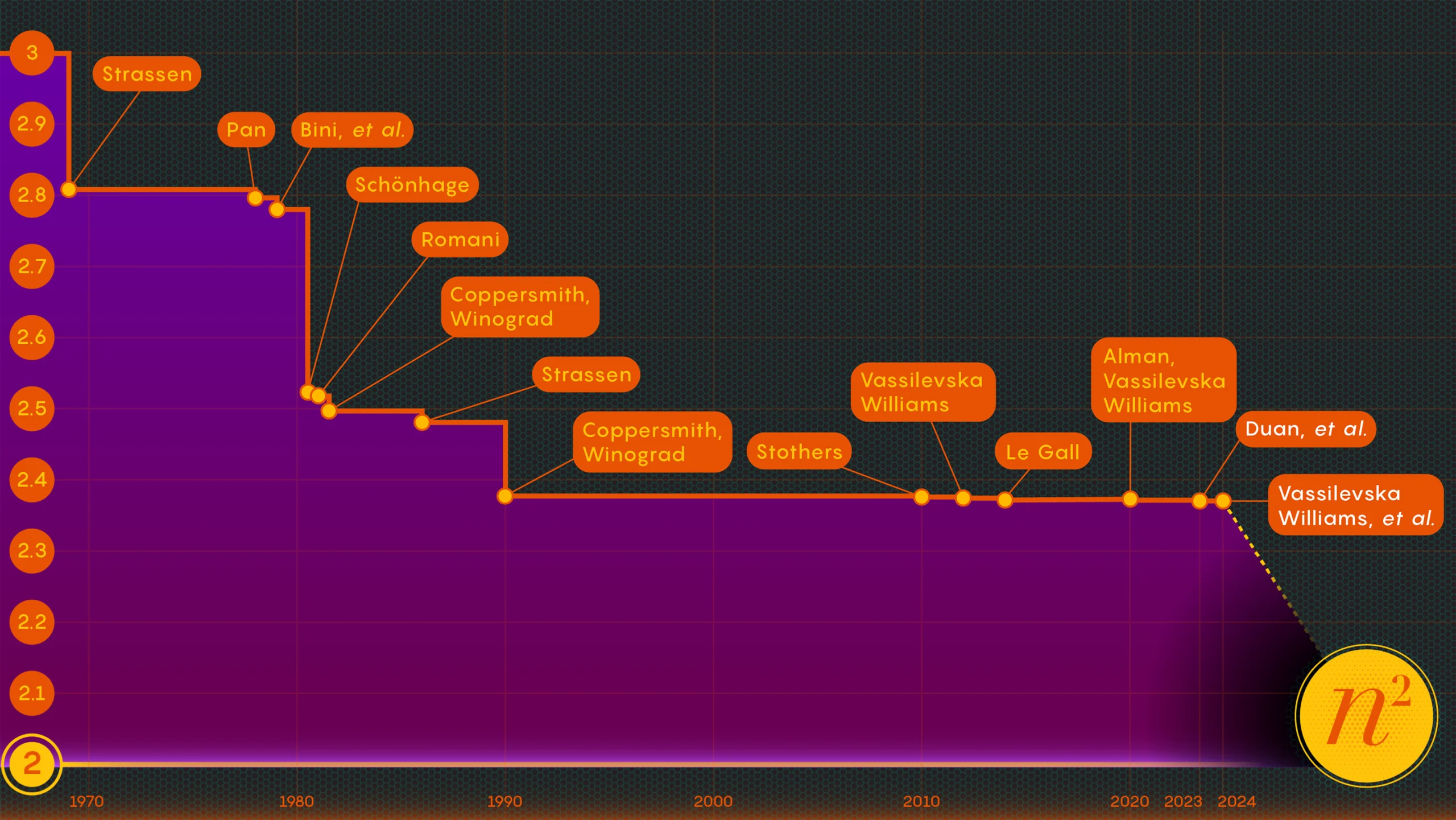
In 1969, the mathematician Volker Strassen revealed a more complicated procedure that could multiply 2-by-2 matrices in just seven multiplicative steps and 18 additions. Two years later, the computer scientist Shmuel Winograd demonstrated that seven is, indeed, the absolute minimum for 2-by-2 matrices.


Merrill Sherman/Quanta Magazine
Strassen exploited that same idea to show that all larger n-by-n matrices can also be multiplied in fewer than n3 steps. A key element in this strategy involves a procedure called decomposition — breaking down a large matrix into successively smaller submatrices, which might end up being as small as 2-by-2 or even 1-by-1 (these are just single numbers).
The rationale for dividing a giant array into tiny pieces is pretty simple, according to Virginia Vassilevska Williams, a computer scientist at the Massachusetts Institute of Technology and co-author of one of the new papers. “It’s hard for a human to look at a large matrix (say, on the order of 100-by-100) and think of the best possible algorithm,” Vassilevska Williams said. Even 3-by-3 matrices haven’t been fully solved yet. “Nevertheless, one can use a fast algorithm that one has already developed for small matrices to also obtain a fast algorithm for larger matrices.”
The key to speed, researchers have determined, is to reduce the number of multiplication steps, lowering that exponent from n3 (for the standard method) as much as they can. The lowest possible value, n2, is basically as long as it takes just to write the answer. Computer scientists refer to that exponent as omega, ω, with nω being the fewest possible steps needed to successfully multiply two n-by-n matrices as n grows very large. “The point of this work,” said Zhou, who also co-authored the January 2024 paper, “is to see how close to 2 you can come, and whether it can be achieved in theory.”
A Laser Focus
In 1986, Strassen had another big breakthrough when he introduced what’s called the laser method for matrix multiplication. Strassen used it to establish an upper value for omega of 2.48. While the method is only one step in large matrix multiplications, it’s one of the most important because researchers have continued to improve upon it.
One year later, Winograd and Don Coppersmith introduced a new algorithm that beautifully complemented the laser method. This combination of tools has featured in virtually all subsequent efforts to speed up matrix multiplication.
Here’s a simplified way of thinking about how these different elements fit together. Let’s start with two large matrices, A and B, that you want to multiply together. First, you decompose them into many smaller submatrices, or blocks, as they’re sometimes called. Next, you can use Coppersmith and Winograd’s algorithm to serve as a kind of instruction manual for handling, and ultimately assembling, the blocks. “It tells me what to multiply and what to add and what entries go where” in the product matrix C, Vassilevska Williams said. “It’s just a recipe to build up C from A and B.”
There is a catch, however: You sometimes end up with blocks that have entries in common. Leaving these in the product would be akin to counting those entries twice, so at some point you need to get rid of those duplicated terms, called overlaps. Researchers do this by “killing” the blocks they’re in — setting their components equal to zero to remove them from the calculation.

Virginia Vassilevska Williams was part of a team that improved upon the new approach to multiply matrices, coming up with the current fastest approach.
Jared Charney
That’s where Strassen’s laser method finally comes into play. “The laser method typically works very well and generally finds a good way to kill a subset of blocks to remove the overlap,” Le Gall said. After the laser has eliminated, or “burned away,” all the overlaps, you can construct the final product matrix, C.
Putting these various techniques together results in an algorithm for multiplying two matrices with a deliberately stingy number of multiplications overall — at least in theory. The laser method is not intended to be practical; it’s just a way to think about the ideal way to multiply matrices. “We never run the method [on a computer],” Zhou said. “We analyze it.”
And that analysis is what led to the biggest improvement to omega in more than a decade.
A Loss Is Found
Last summer’s paper, by Duan, Zhou and Wu, showed that Strassen’s process could still be sped up significantly. It was all because of a concept they called a hidden loss, buried deep within previous analyses — “a result of unintentionally killing too many blocks,” Zhou said.
The laser method works by labeling blocks with overlaps as garbage, slated for disposal; other blocks are deemed worthy and will be saved. The selection process, however, is somewhat randomized. A block rated as garbage may, in fact, turn out to be useful after all. This wasn’t a total surprise, but by examining many of these random choices, Duan’s team determined that the laser method was systematically undervaluing blocks: More blocks should be saved and fewer thrown out. And, as is usually the case, less waste translates into greater efficiency.
“Being able to keep more blocks without overlap thus leads to … a faster matrix multiplication algorithm,” Le Gall said.
After proving the existence of this loss, Duan’s team modified the way that the laser method labeled blocks, reducing the waste substantially. As a result, they set a new upper bound for omega at around 2.371866 — an improvement over the previous upper bound of 2.3728596, set in 2020 by Josh Alman and Vassilevska Williams. That may seem like a modest change, lowering the bound by just about 0.001. But it’s the single biggest improvement scientists have seen since 2010. Vassilevska Williams and Alman’s 2020 result, by comparison, only improved upon its predecessor by 0.00001.
But what’s most exciting for researchers isn’t just the new record itself — which didn’t last long. It’s also the fact that the paper revealed a new avenue for improvement that, until then, had gone totally unnoticed. For nearly four decades, everyone has been relying upon the same laser method, Le Gall said. “Then they found that, well, we can do better.”
The January 2024 paper refined this new approach, enabling Vassilevska Williams, Zhou and their co-authors to further reduce the hidden loss. This led to an additional improvement of omega’s upper bound, reducing it to 2.371552. The authors also generalized that same technique to improve the multiplication process for rectangular (n-by-m) matrices — a procedure that has applications in graph theory, machine learning and other areas.
Some further progress along these lines is all but certain, but there are limits. In 2015, Le Gall and two collaborators proved that the current approach — the laser method coupled with the Coppersmith-Winograd recipe — cannot yield an omega below 2.3078. To make any further improvements, Le Gall said, “you need to improve upon the original [approach] of Coppersmith and Winograd that has not really changed since 1987.” But so far, nobody has come up with a better way. There may not even be one.
“Improving omega is actually part of understanding this problem,” Zhou said. “If we can understand the problem well, then we can design better algorithms for it. [And] people are still in the very early stages of understanding this age-old problem.”



